
首先还是安装必须的 jdk,看到这里,http://os.51cto.com/art/201003…
终端下进入你存放jdk-6u12-linux-i586.bin,例如我的位置是:/home/liangshihong
$ sudo -s ./jdk-6u12-linux-i586.bin
一路回车,直到询问是否安装,输入yes回车
ok,安装完毕,下面配置环境变量
配置classpath,修改所有用户的环境变量
$ sudo gedit /etc/profile
在文件最后添加
#set java environment
JAVA_HOME=/home/liangshihong/jdk1.6.0_12
export JRE_HOME=/home/liangshihong/jdk1.6.0_12/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
重新启动计算机,用命令测试jdk的版本
java -version
显示如下信息:成功安装
java version “1.6.0_12”
Java(TM) SE Runtime Environment (build 1.6.0_12-b04)
Java HotSpot(TM) Server VM (build 11.2-b01, mixed mode)
liangshihong@liangshihong-Imagine:~$
另外需要修改 /etc/hosts
10.241.32.32 cluster-1 10.241.158.17 cluster-2 10.241.158.171 cluster-3
然后需要互相打通集群内的访问,由于我们的目标是,master 需要 ssh 要下面各个 node,而 node 之间不需要互相连接,对于这个需求,可以这么来实现
在 master 上面使用
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
来生成自己的公钥,然后把这个 auth 文件复制到下面的每个 node 就可以了
scp /root/.ssh/authorized_keys cluster-2:~/.ssh/ scp /root/.ssh/authorized_keys cluster-3:~/.ssh/
插入一下 tips,在修改完毕 profile 文件后,执行source /etc/profile 来使其生效。
测试一下,应该就可以实现各个机器之间的无密码访问了,然后开始配置 Hadoop,主要看到这个教程,http://blog.csdn.net/hguisu/ar…
3. 集群配置(所有节点相同)
3.1配置文件:conf/core-site.xml
fs.default.name
hadoop.tmp.dir
/home/hadoop/hadoop_home/var1)fs.default.name是NameNode的URI。hdfs://主机名:端口/
2)hadoop.tmp.dir :Hadoop的默认临时路径,这个最好配置,如果在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的tmp目录即可。不过如果删除了NameNode机器的此目录,那么就需要重新执行NameNode格式化的命令。
3.2配置文件:conf/mapred-site.xml
mapred.job.tracker
node1:49001
mapred.local.dir
/home/hadoop/hadoop_home/var1)mapred.job.tracker是JobTracker的主机(或者IP)和端口。主机:端口。
3.3配置文件:conf/hdfs-site.xml
dfs.name.dir
/home/hadoop/name1, /home/hadoop/name2 #hadoop的name目录路径dfs.data.dir
/home/hadoop/data1, /home/hadoop/data2dfs.replication
21) dfs.name.dir是NameNode持久存储名字空间及事务日志的本地文件系统路径。 当这个值是一个逗号分割的目录列表时,nametable数据将会被复制到所有目录中做冗余备份。
2) dfs.data.dir是DataNode存放块数据的本地文件系统路径,逗号分割的列表。 当这个值是逗号分割的目录列表时,数据将被存储在所有目录下,通常分布在不同设备上。
3)dfs.replication是数据需要备份的数量,默认是3,如果此数大于集群的机器数会出错。
注意:此处的name1、name2、data1、data2目录不能预先创建,hadoop格式化时会自动创建,如果预先创建反而会有问题。3.4配置masters和slaves主从结点
配置conf/masters和conf/slaves来设置主从结点,注意最好使用主机名,并且保证机器之间通过主机名可以互相访问,每个主机名一行。vi masters:
输入:node1
vi slaves:
输入:
node2
node3配置结束,把配置好的hadoop文件夹拷贝到其他集群的机器中,并且保证上面的配置对于其他机器而言正确,例如:如果其他机器的Java安装路径不一样,要修改conf/hadoop-env.sh
$ scp -r /home/hadoop/hadoop-0.20.203 root@node2: /home/hadoop/
对于我,我的 conf/core-site.xml 如下
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://cluster-1:9000</value>
</property>
</configuration>
conf/mapred-site.xml 如下
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>cluster-1:9001</value>
</property>
</configuration>
conf/hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
接下来配置主从节点,修改 conf/masters
cluster-1
和 conf/slaves
cluster-2 cluster-3
然后把配置文件拷贝到其他机器
scp conf/core-site.xml conf/mapred-site.xml conf/hdfs-site.xml conf/masters conf/slaves cluster-2:~/workspace/hadoop-1.1.2/conf scp conf/core-site.xml conf/mapred-site.xml conf/hdfs-site.xml conf/masters conf/slaves cluster-3:~/workspace/hadoop-1.1.2/conf
格式化 namenode
root@cluster-1:~/workspace/hadoop-1.1.2# bin/hadoop namenode -format 13/06/19 10:48:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = cluster-1/10.241.32.32 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.1.2 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.1 -r 1440782; compiled by 'hortonfo' on Thu Jan 31 02:03:24 UTC 2013 ************************************************************/ 13/06/19 10:48:56 INFO util.GSet: VM type = 64-bit 13/06/19 10:48:56 INFO util.GSet: 2% max memory = 19.33375 MB 13/06/19 10:48:56 INFO util.GSet: capacity = 2^21 = 2097152 entries 13/06/19 10:48:56 INFO util.GSet: recommended=2097152, actual=2097152 13/06/19 10:48:56 INFO namenode.FSNamesystem: fsOwner=root 13/06/19 10:48:56 INFO namenode.FSNamesystem: supergroup=supergroup 13/06/19 10:48:56 INFO namenode.FSNamesystem: isPermissionEnabled=true 13/06/19 10:48:56 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100 13/06/19 10:48:56 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s) 13/06/19 10:48:56 INFO namenode.NameNode: Caching file names occuring more than 10 times 13/06/19 10:48:57 INFO common.Storage: Image file of size 110 saved in 0 seconds. 13/06/19 10:48:57 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/tmp/hadoop-root/dfs/name/current/edits 13/06/19 10:48:57 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/tmp/hadoop-root/dfs/name/current/edits 13/06/19 10:48:57 INFO common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted. 13/06/19 10:48:57 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at cluster-1/10.241.32.32 ************************************************************/
如果格式化失败,可以尝试这个命令
root@cluster-1:~/workspace/hadoop-1.1.2# rm -rf /tmp/hadoop-root*
格式化之后,启动集群,在这里,由于我们的 namenode 和 jobtracker 在同一台机器,所以可以这样来启动
root@cluster-1:~/workspace/hadoop-1.1.2# bin/start-all.sh starting namenode, logging to /root/workspace/hadoop-1.1.2/libexec/../logs/hadoop-root-namenode-cluster-1.out cluster-2: starting datanode, logging to /root/workspace/hadoop-1.1.2/libexec/../logs/hadoop-root-datanode-cluster-2.out cluster-3: starting datanode, logging to /root/workspace/hadoop-1.1.2/libexec/../logs/hadoop-root-datanode-cluster-3.out cluster-1: starting secondarynamenode, logging to /root/workspace/hadoop-1.1.2/libexec/../logs/hadoop-root-secondarynamenode-cluster-1.out starting jobtracker, logging to /root/workspace/hadoop-1.1.2/libexec/../logs/hadoop-root-jobtracker-cluster-1.out cluster-2: starting tasktracker, logging to /root/workspace/hadoop-1.1.2/libexec/../logs/hadoop-root-tasktracker-cluster-2.out cluster-3: starting tasktracker, logging to /root/workspace/hadoop-1.1.2/libexec/../logs/hadoop-root-tasktracker-cluster-3.out
由于在配置 conf/hdfs-site.xml 的时候,我们没有配置 dfs.data.dir,所以,datanode 中,数据的存放位置是 /tmp,我们可以在 cluster-2 和 clutster-3 中看到
root@cluster-2:/tmp# ll total 32 drwxrwxrwt 6 root root 4096 2013-06-19 10:57 ./ drwxr-xr-x 21 root root 4096 2013-06-18 17:03 ../ drwxr-xr-x 4 root root 4096 2013-06-19 10:52 hadoop-root/ -rw-r--r-- 1 root root 5 2013-06-19 10:57 hadoop-root-datanode.pid -rw-r--r-- 1 root root 5 2013-06-19 10:57 hadoop-root-tasktracker.pid
root@cluster-3:/tmp# ll total 32 drwxrwxrwt 6 root root 4096 2013-06-19 10:57 ./ drwxr-xr-x 21 root root 4096 2013-06-18 17:18 ../ drwxr-xr-x 4 root root 4096 2013-06-19 10:52 hadoop-root/ -rw-r--r-- 1 root root 5 2013-06-19 10:57 hadoop-root-datanode.pid -rw-r--r-- 1 root root 5 2013-06-19 10:57 hadoop-root-tasktracker.pid
同样可以通过 web 来看到集群的情况
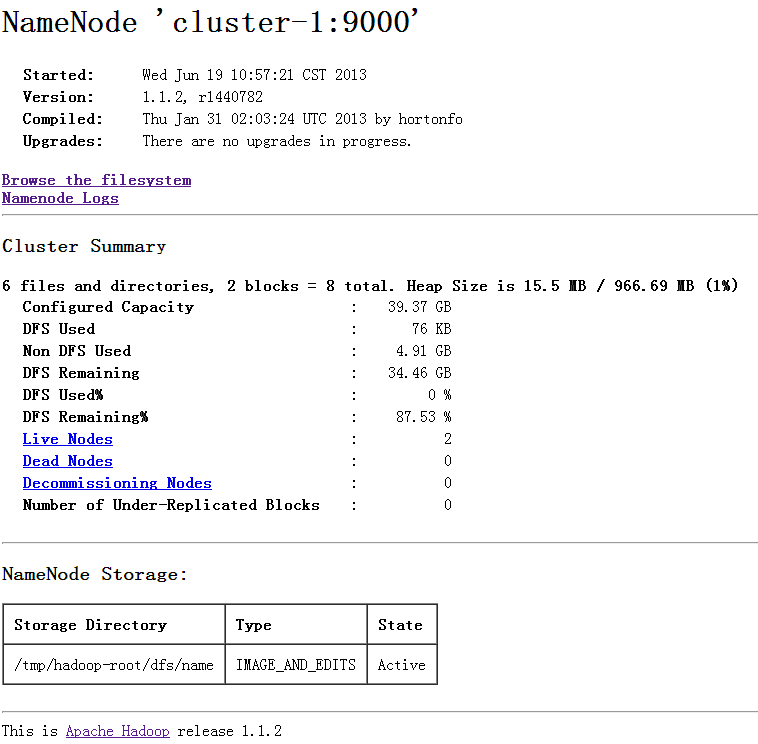
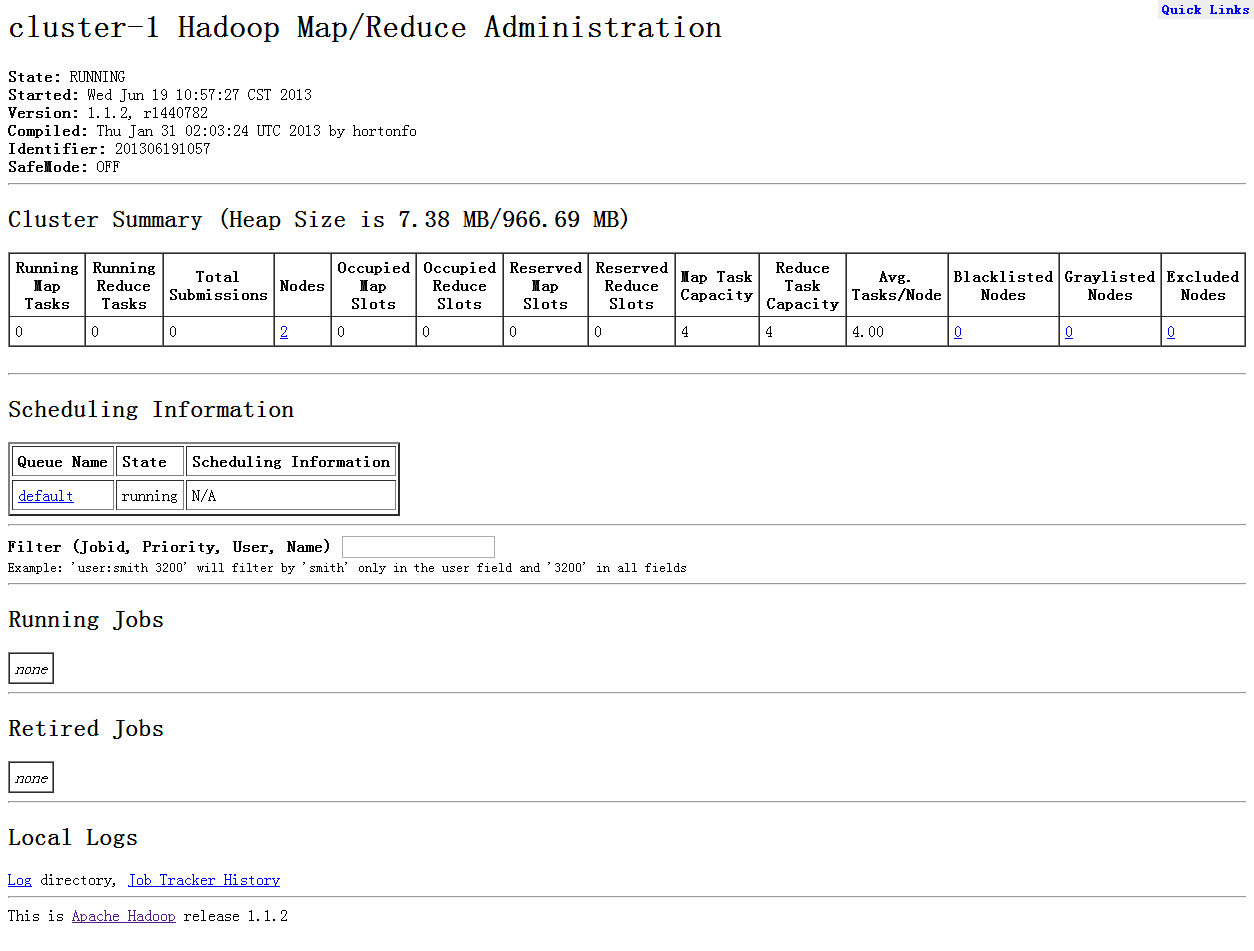
然后运行官方教程的例程,http://hadoop.apache.org/docs/…
Copy the input files into the distributed filesystem:
$ bin/hadoop fs -put conf inputRun some of the examples provided:
$ bin/hadoop jar hadoop-examples-*.jar grep input output ‘dfs[a-z.]+’Examine the output files:
Copy the output files from the distributed filesystem to the local filesytem and examine them:
$ bin/hadoop fs -get output output
$ cat output/*or
View the output files on the distributed filesystem:
$ bin/hadoop fs -cat output/*
首先拷贝文件
root@cluster-1:~/workspace/hadoop-1.1.2# bin/hadoop fs -put conf input root@cluster-1:~/workspace/hadoop-1.1.2# bin/hadoop fs -ls input Found 16 items -rw-r--r-- 2 root supergroup 7457 2013-06-19 11:14 /user/root/input/capacity-scheduler.xml -rw-r--r-- 2 root supergroup 535 2013-06-19 11:14 /user/root/input/configuration.xsl -rw-r--r-- 2 root supergroup 294 2013-06-19 11:14 /user/root/input/core-site.xml -rw-r--r-- 2 root supergroup 327 2013-06-19 11:14 /user/root/input/fair-scheduler.xml -rw-r--r-- 2 root supergroup 2240 2013-06-19 11:14 /user/root/input/hadoop-env.sh -rw-r--r-- 2 root supergroup 1488 2013-06-19 11:14 /user/root/input/hadoop-metrics2.properties -rw-r--r-- 2 root supergroup 4644 2013-06-19 11:14 /user/root/input/hadoop-policy.xml -rw-r--r-- 2 root supergroup 274 2013-06-19 11:14 /user/root/input/hdfs-site.xml -rw-r--r-- 2 root supergroup 4441 2013-06-19 11:14 /user/root/input/log4j.properties -rw-r--r-- 2 root supergroup 2033 2013-06-19 11:14 /user/root/input/mapred-queue-acls.xml -rw-r--r-- 2 root supergroup 290 2013-06-19 11:14 /user/root/input/mapred-site.xml -rw-r--r-- 2 root supergroup 10 2013-06-19 11:14 /user/root/input/masters -rw-r--r-- 2 root supergroup 20 2013-06-19 11:14 /user/root/input/slaves -rw-r--r-- 2 root supergroup 1243 2013-06-19 11:14 /user/root/input/ssl-client.xml.example -rw-r--r-- 2 root supergroup 1195 2013-06-19 11:14 /user/root/input/ssl-server.xml.example -rw-r--r-- 2 root supergroup 382 2013-06-19 11:14 /user/root/input/taskcontroller.cfg
然后运行例程
root@cluster-1:~/workspace/hadoop-1.1.2# bin/hadoop jar hadoop-examples-*.jar grep input output 'dfs[a-z.]+' 13/06/19 11:14:49 INFO util.NativeCodeLoader: Loaded the native-hadoop library 13/06/19 11:14:49 WARN snappy.LoadSnappy: Snappy native library not loaded 13/06/19 11:14:49 INFO mapred.FileInputFormat: Total input paths to process : 16 13/06/19 11:14:50 INFO mapred.JobClient: Running job: job_201306191057_0001 13/06/19 11:14:51 INFO mapred.JobClient: map 0% reduce 0% 13/06/19 11:15:01 INFO mapred.JobClient: map 12% reduce 0% 13/06/19 11:15:02 INFO mapred.JobClient: map 25% reduce 0% 13/06/19 11:15:08 INFO mapred.JobClient: map 37% reduce 0% 13/06/19 11:15:09 INFO mapred.JobClient: map 50% reduce 0% 13/06/19 11:15:14 INFO mapred.JobClient: map 62% reduce 0% 13/06/19 11:15:17 INFO mapred.JobClient: map 75% reduce 0% 13/06/19 11:15:19 INFO mapred.JobClient: map 87% reduce 0% 13/06/19 11:15:20 INFO mapred.JobClient: map 87% reduce 20% 13/06/19 11:15:26 INFO mapred.JobClient: map 100% reduce 29% 13/06/19 11:15:33 INFO mapred.JobClient: map 100% reduce 100% 13/06/19 11:15:36 INFO mapred.JobClient: Job complete: job_201306191057_0001 13/06/19 11:15:36 INFO mapred.JobClient: Counters: 30 13/06/19 11:15:36 INFO mapred.JobClient: Job Counters 13/06/19 11:15:36 INFO mapred.JobClient: Launched reduce tasks=1 13/06/19 11:15:36 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=110582 13/06/19 11:15:36 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 13/06/19 11:15:36 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 13/06/19 11:15:36 INFO mapred.JobClient: Launched map tasks=16 13/06/19 11:15:36 INFO mapred.JobClient: Data-local map tasks=16 13/06/19 11:15:36 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=31899 13/06/19 11:15:36 INFO mapred.JobClient: File Input Format Counters 13/06/19 11:15:36 INFO mapred.JobClient: Bytes Read=26873 13/06/19 11:15:36 INFO mapred.JobClient: File Output Format Counters 13/06/19 11:15:36 INFO mapred.JobClient: Bytes Written=180 13/06/19 11:15:36 INFO mapred.JobClient: FileSystemCounters 13/06/19 11:15:36 INFO mapred.JobClient: FILE_BYTES_READ=82 13/06/19 11:15:36 INFO mapred.JobClient: HDFS_BYTES_READ=28595 13/06/19 11:15:36 INFO mapred.JobClient: FILE_BYTES_WRITTEN=866947 13/06/19 11:15:36 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=180 13/06/19 11:15:36 INFO mapred.JobClient: Map-Reduce Framework 13/06/19 11:15:36 INFO mapred.JobClient: Map output materialized bytes=172 13/06/19 11:15:36 INFO mapred.JobClient: Map input records=759 13/06/19 11:15:36 INFO mapred.JobClient: Reduce shuffle bytes=172 13/06/19 11:15:36 INFO mapred.JobClient: Spilled Records=6 13/06/19 11:15:36 INFO mapred.JobClient: Map output bytes=70 13/06/19 11:15:36 INFO mapred.JobClient: Total committed heap usage (bytes)=2703933440 13/06/19 11:15:36 INFO mapred.JobClient: CPU time spent (ms)=5950 13/06/19 11:15:36 INFO mapred.JobClient: Map input bytes=26873 13/06/19 11:15:36 INFO mapred.JobClient: SPLIT_RAW_BYTES=1722 13/06/19 11:15:36 INFO mapred.JobClient: Combine input records=3 13/06/19 11:15:36 INFO mapred.JobClient: Reduce input records=3 13/06/19 11:15:36 INFO mapred.JobClient: Reduce input groups=3 13/06/19 11:15:36 INFO mapred.JobClient: Combine output records=3 13/06/19 11:15:36 INFO mapred.JobClient: Physical memory (bytes) snapshot=2599989248 13/06/19 11:15:36 INFO mapred.JobClient: Reduce output records=3 13/06/19 11:15:36 INFO mapred.JobClient: Virtual memory (bytes) snapshot=7510061056 13/06/19 11:15:36 INFO mapred.JobClient: Map output records=3 13/06/19 11:15:36 INFO mapred.FileInputFormat: Total input paths to process : 1 13/06/19 11:15:36 INFO mapred.JobClient: Running job: job_201306191057_0002 13/06/19 11:15:37 INFO mapred.JobClient: map 0% reduce 0% 13/06/19 11:15:44 INFO mapred.JobClient: map 100% reduce 0% 13/06/19 11:15:52 INFO mapred.JobClient: map 100% reduce 33% 13/06/19 11:15:54 INFO mapred.JobClient: map 100% reduce 100% 13/06/19 11:15:55 INFO mapred.JobClient: Job complete: job_201306191057_0002 13/06/19 11:15:55 INFO mapred.JobClient: Counters: 30 13/06/19 11:15:55 INFO mapred.JobClient: Job Counters 13/06/19 11:15:55 INFO mapred.JobClient: Launched reduce tasks=1 13/06/19 11:15:55 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=7370 13/06/19 11:15:55 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 13/06/19 11:15:55 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 13/06/19 11:15:55 INFO mapred.JobClient: Launched map tasks=1 13/06/19 11:15:55 INFO mapred.JobClient: Data-local map tasks=1 13/06/19 11:15:55 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=9828 13/06/19 11:15:55 INFO mapred.JobClient: File Input Format Counters 13/06/19 11:15:55 INFO mapred.JobClient: Bytes Read=180 13/06/19 11:15:55 INFO mapred.JobClient: File Output Format Counters 13/06/19 11:15:55 INFO mapred.JobClient: Bytes Written=52 13/06/19 11:15:55 INFO mapred.JobClient: FileSystemCounters 13/06/19 11:15:55 INFO mapred.JobClient: FILE_BYTES_READ=82 13/06/19 11:15:55 INFO mapred.JobClient: HDFS_BYTES_READ=296 13/06/19 11:15:55 INFO mapred.JobClient: FILE_BYTES_WRITTEN=100437 13/06/19 11:15:55 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=52 13/06/19 11:15:55 INFO mapred.JobClient: Map-Reduce Framework 13/06/19 11:15:55 INFO mapred.JobClient: Map output materialized bytes=82 13/06/19 11:15:55 INFO mapred.JobClient: Map input records=3 13/06/19 11:15:55 INFO mapred.JobClient: Reduce shuffle bytes=82 13/06/19 11:15:55 INFO mapred.JobClient: Spilled Records=6 13/06/19 11:15:55 INFO mapred.JobClient: Map output bytes=70 13/06/19 11:15:55 INFO mapred.JobClient: Total committed heap usage (bytes)=210501632 13/06/19 11:15:55 INFO mapred.JobClient: CPU time spent (ms)=1090 13/06/19 11:15:55 INFO mapred.JobClient: Map input bytes=94 13/06/19 11:15:55 INFO mapred.JobClient: SPLIT_RAW_BYTES=116 13/06/19 11:15:55 INFO mapred.JobClient: Combine input records=0 13/06/19 11:15:55 INFO mapred.JobClient: Reduce input records=3 13/06/19 11:15:55 INFO mapred.JobClient: Reduce input groups=1 13/06/19 11:15:55 INFO mapred.JobClient: Combine output records=0 13/06/19 11:15:55 INFO mapred.JobClient: Physical memory (bytes) snapshot=227721216 13/06/19 11:15:55 INFO mapred.JobClient: Reduce output records=3 13/06/19 11:15:55 INFO mapred.JobClient: Virtual memory (bytes) snapshot=898035712 13/06/19 11:15:55 INFO mapred.JobClient: Map output records=3
查看结果
root@cluster-1:~/workspace/hadoop-1.1.2# bin/hadoop fs -cat output/* 1 dfs.replication 1 dfs.server.namenode. 1 dfsadmin
至此,Hadoop 的集群版本环境搭建完成
附上一个配置文件说明的文档,http://www.cnblogs.com/serendi…
—————————————–
2013-06-19 16:35:52 update 修改了配置文件 conf/hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/var/local/hadoop/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/var/local/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
然后重新格式化
root@cluster-1:~/workspace/hadoop-1.1.2# bin/hadoop namenode -format 13/06/19 16:33:38 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = cluster-1/10.241.32.32 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.1.2 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.1 -r 1440782; compiled by 'hortonfo' on Thu Jan 31 02:03:24 UTC 2013 ************************************************************/ 13/06/19 16:33:38 INFO util.GSet: VM type = 64-bit 13/06/19 16:33:38 INFO util.GSet: 2% max memory = 19.33375 MB 13/06/19 16:33:38 INFO util.GSet: capacity = 2^21 = 2097152 entries 13/06/19 16:33:38 INFO util.GSet: recommended=2097152, actual=2097152 13/06/19 16:33:39 INFO namenode.FSNamesystem: fsOwner=root 13/06/19 16:33:39 INFO namenode.FSNamesystem: supergroup=supergroup 13/06/19 16:33:39 INFO namenode.FSNamesystem: isPermissionEnabled=true 13/06/19 16:33:39 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100 13/06/19 16:33:39 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s) 13/06/19 16:33:39 INFO namenode.NameNode: Caching file names occuring more than 10 times 13/06/19 16:33:39 INFO common.Storage: Image file of size 110 saved in 0 seconds. 13/06/19 16:33:40 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/var/local/hadoop/name/current/edits 13/06/19 16:33:40 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/var/local/hadoop/name/current/edits 13/06/19 16:33:40 INFO common.Storage: Storage directory /var/local/hadoop/name has been successfully formatted. 13/06/19 16:33:40 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at cluster-1/10.241.32.32 ************************************************************/
格式化之后,会在 master 的 /var/local 下面自动建立 hadoop/name
然后启动集群,启动之后,会自动在各个 node 的 /var/local 下面建立 hadoop/data
于是例程的输出也有了变化
root@cluster-1:~/workspace/hadoop-1.1.2# bin/hadoop fs -cat output/* 1 dfs.data.dir 1 dfs.name.dir 1 dfs.replication 1 dfs.server.namenode. 1 dfsadmin
在namenode启动脚本%HADOOP_HOME%/bin/start-dfs.sh的时候发现datanode报错:
Error: JAVA_HOME is not set
原因是在%HADOOP_HOME%/conf/hadoop-env.sh内缺少JAVA_HOME的定义,只需要在hadoop-env.sh中增加:
JAVA_HOME=/your/jdk/root/path
周一发现hadoop集群down掉了(FSNamesystem.java:296) (NameNode.java:283)
发现由于磁盘已满100%
删除无用文件后重启集群,发现还是起不来,错误如下:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = SFserver141.localdomain/192.168.15.141
STARTUP_MSG: args = []
STARTUP_MSG: version = 0.20.3-SNAPSHOT
STARTUP_MSG: build = -r ; compiled by ‘root’ on Wed Jun 8 12:43:33 CST 2011
************************************************************/
2012-10-22 08:50:42,096 INFO org.apache.hadoop.ipc.metrics.RpcMetrics: Initializing RPC Metrics with hostName=NameNode, port=9000
2012-10-22 08:50:42,104 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: Namenode up at: SFserver141.localdomain/192.168.15.141:9000
2012-10-22 08:50:42,112 INFO org.apache.hadoop.metrics.jvm.JvmMetrics: Initializing JVM Metrics with processName=NameNode, sessionId=null
2012-10-22 08:50:42,113 INFO org.apache.hadoop.hdfs.server.namenode.metrics.NameNodeMetrics: Initializing NameNodeMeterics using context object:org.apache.hadoop.metrics.spi.NullContext
2012-10-22 08:50:42,169 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: fsOwner=root,root,bin,daemon,sys,adm,disk,wheel
2012-10-22 08:50:42,169 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: supergroupsupergroup=supergroup
2012-10-22 08:50:42,169 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: isPermissionEnabled=false
2012-10-22 08:50:42,187 INFO org.apache.hadoop.hdfs.server.namenode.metrics.FSNamesystemMetrics: Initializing FSNamesystemMetrics using context object:org.apache.hadoop.metrics.spi.NullContext
2012-10-22 08:50:42,188 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Registered FSNamesystemStatusMBean
2012-10-22 08:50:42,248 INFO org.apache.hadoop.hdfs.server.common.Storage: Number of files = 799968
2012-10-22 08:50:47,535 INFO org.apache.hadoop.hdfs.server.common.Storage: Number of files under construction = 13
2012-10-22 08:50:47,540 INFO org.apache.hadoop.hdfs.server.common.Storage: Image file of size 102734547 loaded in 5 seconds.
2012-10-22 08:50:48,131 INFO org.apache.hadoop.hdfs.server.common.Storage: Edits file /data/java/hadoop020/data/dfs.name.dir/current/edits of size 2749136 edits # 17772 loaded in 0 seconds.
2012-10-22 08:50:48,801 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: java.lang.NumberFormatException: For input string: “”
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:48)
at java.lang.Integer.parseInt(Integer.java:470)
at java.lang.Short.parseShort(Short.java:120)
at java.lang.Short.parseShort(Short.java:78)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.readShort(FSEditLog.java:1311)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.loadFSEdits(FSEditLog.java:541)
at org.apache.hadoop.hdfs.server.namenode.FSImage.loadFSEdits(FSImage.java:1011)
at org.apache.hadoop.hdfs.server.namenode.FSImage.loadFSImage(FSImage.java:826)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:364)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.loadFSImage(FSDirectory.java:87)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.initialize(FSNamesystem.java:315)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:205)
at org.apache.hadoop.hdfs.server.namenode.NameNode.
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:986)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:995)
2012-10-22 08:50:48,802 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at SFserver141.localdomain/192.168.15.141
************************************************************/
大致是因为edits这个文件出现问题;
上网查了不少文档,但由于没有设置secondarynamenode;所以没有edits的镜像文件
之后发现一篇文章写:
printf “\xff\xff\xff\xee\xff” > edits
把上面一段字符串写到edits文件中
重启正常
注:dfs.name.dir/current文件夹下还出现了edits.new的文件,我是删除的 不知道有没有影响
本文出自 “工作笔记” 博客,请务必保留此出处http://693340562.blog.51cto.com/1125757/1033582
Pingback: hadoop 2.5.2 集群安装 | ZRJ