
昨天写了一个 AC 自动机的模版题,现在,我们需要基于这个模版,实现一个多模匹配的 map,具体是这样的,我们给一个 map<string, int>,然后给一个串,要求在这个串里面,把 map 中含有的 key 的 value 都返回出来。
注意到昨天的模版题的实现,是会去改动树本身的,同时也没有做一些内存管理方面的处理,另外的区别是昨天的题是考虑多个相同关键字的,而这个,由于 map 的 key 的唯一性,自然是不允许多个相同的 key 的,那么修改之后如下:
#include <iostream>
#include <stdio.h>
#include <memory.h>
#include <string>
#include <queue>
#include <set>
#define CHAR_COUNT 128
class Node {
public:
Node() {
memset(this, 0, sizeof(*this));
}
char ch;
Node* fail;
Node* next[CHAR_COUNT];
bool end;
int value;
};
class Trie {
public:
Node* root;
Trie() {
root = new Node();
}
~Trie() {
clear(root);
}
void insert(const char* strKey, int value) {
Node* p = root;
for (int i = 0; strKey[i]; i++) {
char ch = strKey[i];
if (p->next[ch] == NULL) {
p->next[ch] = new Node();
}
p = p->next[ch];
p->ch = strKey[i];
}
p->end = true;
p->value = value;
}
void build() {
std::queue<Node*> q;
q.push(root);
while ( ! q.empty()) {
Node* tmp = q.front();
q.pop();
for (int i = 0; i < CHAR_COUNT; i++) {
if (tmp->next[i]) {
if (tmp == root) {
tmp->next[i]->fail = root;
} else {
Node* p = tmp->fail;
while (p) {
if (p->next[i]) {
tmp->next[i]->fail = p->next[i];
break;
}
p = p->fail;
}
if ( ! p) {
tmp->next[i]->fail = root;
}
}
q.push(tmp->next[i]);
}
}
}
}
std::vector<int> query(const char* str) {
std::vector<int> result;
Node* p = root;
for (int i = 0; str[i]; i++) {
char ch = str[i];
while ( ! p->next[ch] && p != root) {
p = p->fail;
}
p = p->next[ch];
if ( ! p) {
p = root;
}
Node* tmp = p;
while (tmp != root) {
if (tmp->end) {
result.push_back(tmp->value);
}
tmp = tmp->fail;
}
}
return result;
}
void clear(Node*& p) {
if (p) {
for (int i = 0; i < CHAR_COUNT; i++) {
clear(p->next[i]);
}
delete p;
p = NULL;
}
}
};
int main() {
int t;
scanf("%d", &t);
while (t--) {
Trie trie;
int n;
scanf("%d", &n);
while (n--) {
std::string keyword;
int value;
std::cin>>keyword>>value;
trie.insert(keyword.c_str(), value);
}
trie.build();
std::string query;
std::cin>>query;
std::vector<int> result = trie.query(query.c_str());
printf("size %d\n", result.size());
for (std::vector<int>::iterator it = result.begin(); it != result.end(); it++) {
printf("%d\n", *it);
}
}
return 0;
}
对于这个实现,思路上应该是没有问题,但是,看一下下面这个测试用例。
1 2 11 11 111 111 111
他的输出却是这个样子的
size 3 11 111 11
嗯,11 这个 value 出现了两次。
让我们来分析一下,模拟程序的运行过程,看看是什么情况。
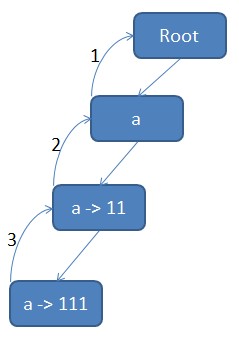
首先给出失败指针的结果图如上,我们来看看这个失败指针是怎么得出来的。
- 第 50 行,把 root 节点加入队列(root 节点的失败指针是 NULL),然后进入 51 行开始的队列处理循环
- 取出 root 节点,根据 56 – 58 行,对 root 节点的所有直接子节点,将其失败指针指向 root,对应图上的失败指针 1。同时 71 行将 root 节点的所有子节点追加入队列。至此,队列中有一个节点,也就是第一个 a 节点。
- 回到 52 行,取出第一个 a 节点,开始处理。注意到在 54 – 73 行的 for 循环中,tmp 指针是一直不会发生变化的,所以,这个 tmp 指针,可以理解成“当前父节点”,而在此轮循环中,任务就是为这个“当前父节点”的全部非空子节点找好失败指针。那么,对于第一个 a 节点,代码走到 59 行,指针 p 指向第一个 a 节点的失败指针,也就是 root,然后进入 60 – 66 的 while 循环。由于 root 节点有一个字符为 a 的子节点,于是在第一轮的循环中,就为第二个 a 节点找好了失败指针,也就是让第二个 a 节点的失败指针指向第一个 a 节点。
- 第二个 a 节点成为“当前父节点”,同理,为其子节点(也就是第三个 a 节点)找到的失败指针指向了第二个 a 节点。至此所有失败指针建立完成。
回到 60 – 66 行这个 while 循环,为什么这个循环就能可以建立出正确的失败指针呢。这个 while 循环的原理是:一级一级的沿着失败指针回溯,直到某一个节点的包含有跟“当前父节点”相同字符的子节点(61 行)并把“当前父节点”的对应子节点的失败指针指向这个找到的子节点(62 行)并跳出循环(63 行)或者一直找到空节点(65 行)为止。
那么,这样一来,就可以保证,为“当前父节点”的所有子节点找到的失败指针,指向的节点的字符,都是跟这个子节点一样的,而父节点的失败指针,也在上一轮的 BFS 遍历中,指向了一个跟父节点含有相同字符(或者)跟节点的指针,那么,递归的,就可以保证,从那个找到的失败指针往上走,关键词的字符顺序是跟当前路径下来的字符顺序是能匹配(后缀是匹配的)的,所以,失败指针就能据此正确的建立起来。
然后让我们来看一下查询的过程:
- 对于第一个字母,走到第一个 a 节点,沿着失败指针找,找到 root,跳出
- 对于第二个字母,走到第二个 a 节点,然后他的 end 标志是 true 的,于是把这个节点的 value 值 11 加入结果集,沿着失败指针,找到第一个 a 节点,再沿着失败指针,找到 root 节点,跳出
- 对于第三个字母,走到第三个 a 节点,并发现第三个 a 节点的 end 标志是 true,于是把这个节点的 value 值 111 加入结果集,并继续沿着失败指针,找到第二个 a 节点,发现他是 end 的,于是将 11 加入结果集,再沿着失败指针,找到第一个 a 节点和 root 节点,跳出。
注意到悲剧就在第三步的“沿着失败指针回溯”这个环节上,再回到的了第二个 a 节点那里,昨天那个版本之所以不存在这个问题,是因为他在每次加入之后,都把那个节点的 prefix 置为了 -1 并且在循环的时候检查这个 prefix,但是这样就污染了树的内容,从而不利于多次查询。
那么为什么他这里需要沿着失败指针一直回溯呢?回想到之前建立失败指针的过程,由于一个节点下面,失败指针只有一个,这个指针将会指向第一个被找到的具有相同后缀的节点上,但是,无法排除还有其他相同后缀的节点,而这些节点要怎么去关联起来呢,就靠那个被指向的失败节点的失败指针继续往后了,有点链表的感觉,所以,在查询的时候,也需要沿着这些失败指针,一直回溯,直到找到 root 节点为止。
至此基本上就明白了,至于解决方法,我想到的办法也很简单,其实就是在 end 节点上保存这个 key 的 string,然后查询的时候用一个 map 来存放中间结果就可以了。
修改之后的代码也放一份吧:
#include <iostream>
#include <stdio.h>
#include <memory.h>
#include <string>
#include <queue>
#include <map>
#include <set>
#define CHAR_COUNT 128
class Node {
public:
Node() {
ch = 0;
fail = NULL;
memset(next, NULL, sizeof(next));
end = false;
key = "";
value = 0;
}
char ch;
Node* fail;
Node* next[CHAR_COUNT];
bool end;
std::string key;
int value;
};
class Trie {
public:
Node* root;
Trie() {
root = new Node();
}
~Trie() {
clear(root);
}
void insert(const char* strKey, int value) {
Node* p = root;
for (int i = 0; strKey[i]; i++) {
char ch = strKey[i];
if (p->next[ch] == NULL) {
p->next[ch] = new Node();
}
p = p->next[ch];
p->ch = strKey[i];
}
p->end = true;
p->key.assign(strKey);
p->value = value;
}
void build() {
std::queue<Node*> q;
q.push(root);
while ( ! q.empty()) {
Node* tmp = q.front();
q.pop();
for (int i = 0; i < CHAR_COUNT; i++) {
if (tmp->next[i]) {
if (tmp == root) {
tmp->next[i]->fail = root;
} else {
Node* p = tmp->fail;
while (p) {
if (p->next[i]) {
tmp->next[i]->fail = p->next[i];
break;
}
p = p->fail;
}
if ( ! p) {
tmp->next[i]->fail = root;
}
}
q.push(tmp->next[i]);
}
}
}
}
std::map<std::string, int> query(const char* str) {
std::map<std::string, int> result;
Node* p = root;
for (int i = 0; str[i]; i++) {
char ch = str[i];
while ( ! p->next[ch] && p != root) {
p = p->fail;
}
p = p->next[ch];
if ( ! p) {
p = root;
}
Node* tmp = p;
while (tmp != root) {
if (tmp->end) {
result[tmp->key] = tmp->value;
}
tmp = tmp->fail;
}
}
return result;
}
void clear(Node*& p) {
if (p) {
for (int i = 0; i < CHAR_COUNT; i++) {
clear(p->next[i]);
}
delete p;
p = NULL;
}
}
};
int main() {
int t;
scanf("%d", &t);
while (t--) {
Trie trie;
int n;
scanf("%d", &n);
while (n--) {
std::string keyword;
int value;
std::cin>>keyword>>value;
trie.insert(keyword.c_str(), value);
}
trie.build();
std::string query;
std::cin>>query;
std::map<std::string, int> result = trie.query(query.c_str());
printf("size %d\n", result.size());
for (std::map<std::string, int>::iterator it = result.begin(); it != result.end(); it++) {
printf("%s -> %d\n", it->first.c_str(), it->second);
}
}
return 0;
}
稍微注意一下,由于结构体里面有了 stl 容器 string,所以不能再用 memset 来初始化整个结构体了。
虽不明但觉厉…
其实这个还是很有应用价值的,例如说,发微博,或者留言的时候,需要敏感词过滤,敏感词可能有成千上万个,一条留言大约两三百个字符,你总不能循环的调用成千上万次的 str find 函数吧,这个时候就要靠这个 ac 自动机了
这个就是那个论文的东西?
啥论文。。怎么会扯到论文去了